‘트랜스레이트젬마(TranslateGemma)’: 새로운 개방형 번역 모델 제품군

오늘 구글은 젬마 3(Gemma 3)를 기반으로 구축된 새로운 개방형 번역 모델 제품군 트랜스레이트젬마(TranslateGemma)를 소개합니다. 40억(4B), 120억(12B), 270억(27B) 파라미터 크기로 제공되는 이 모델은 개방형 번역 기술의 중요한 진전으로, 이용자가 장소나 디바이스 사양에 구애받지 않고 전 세계 55개 언어로 자유롭게 소통할 수 있도록 돕습니다.
구글은 가장 진보된 대규모 모델의 지식을, 컴팩트하면서도 고성능 개방형 모델로 정제(distilling)함으로써 효율성과 품질 어느 하나도 놓치지 않는 최적의 제품군을 완성했습니다.
두 배 크기의 모델을 능가하는 성능
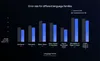
기술 평가에서 가장 주목할 점은 모델들의 탁월한 효율성입니다. 구글의 특화된 학습 과정을 통해, 120억(12B) 트랜스레이트젬마 모델은 WMT24++ 벤치마크에서 메트릭X(MetricX) 기준으로 젬마 3의 270억(27B) 베이스라인 모델을 능가하는 성능을 기록했습니다.
이는 개발자들에게 시사하는 바가 큽니다. 베이스라인 모델의 절반도 안 되는 파라미터만으로도 고품질 번역을 구현할 수 있기 때문입니다. 이러한 효율성의 혁신은 번역의 정확도를 유지하면서도 더 많은 처리량과 더 낮은 지연 시간을 가능케 합니다. 또한 가장 작은 40억(4B) 모델 역시 120억(12B) 베이스라인 모델에 필적하는 성능을 보여주며, 모바일 환경에서의 추론에 적합한 강력한 선택지임을 입증했습니다.
트랜스레이트젬마는 고자원, 중자원, 저자원 언어(high-, mid- and low-resource languages)를 모두 아우르는 55개 언어로 구성된 WMT24++ 데이터셋에서 모델을 테스트했습니다. 그 결과, 트랜스레이트젬마는 모든 언어에서 베이스라인 모델 대비 에러율을 획기적으로 낮추며, 더 높은 효율성으로 향상된 품질을 달성했습니다.
제미나이로 완성된 기술
이처럼 컴팩트한 모델 안에 높은 밀도의 지능을 담을 수 있었던 비결은 구글 제미나이 모델의 ‘직관(intuition)’을 개방형 아키텍처로 이식하는 특화된 2단계 미세 조정 과정에 있습니다.
- 지도 미세 조정(Supervised Fine-Tuning, SFT): 기본 젬마 3 모델을 다양한 병렬 데이터셋으로 미세 조정했습니다. 여기에는 사람이 번역한 텍스트뿐만 아니라, 최신 제미나이 모델이 생성한 고품질의 합성 번역(synthetic translations) 데이터가 풍부하게 포함되어 있어, 데이터가 부족한 저자원 언어에서도 광범위한 언어 커버리지와 높은 정확도를 확보했습니다.
- 강화 학습(Reinforcement Learning, RL): 번역 품질의 정교함을 더하기 위해 새로운 강화 학습 단계를 도입했습니다. 메트릭X-QE(MetricX-QE) 및 오토MQM(AutoMQM)과 같은 고급 지표를 포함한 보상 모델 앙상블을 적용해 모델이 문맥에 맞고 더욱 자연스러운 번역을 생성하도록 최적화했습니다.
전례 없는 언어 지원 범위와 확장성
트랜스레이트젬마는 스페인어, 프랑스어, 중국어, 힌디어와 같은 주요 언어는 물론, 다수의 저자원 언어를 포함한 55개 언어 쌍(language pairs)에 대한 철저한 훈련과 평가를 거쳐 신뢰할 수 있는 고품질 성능을 확보했습니다.
나아가 구글은 핵심 언어 외에도 약 500개의 추가 언어 쌍에 대한 훈련을 진행하며 지원 범위를 확장하고 있습니다. 트랜스레이트젬마는 연구자들이 특정 언어 쌍에 맞춰 자체적인 최신(SOTA) 모델을 미세 조정하거나 저자원 언어 품질을 개선할 수 있도록 설계된 견고한 출발점입니다. 이 확장된 언어 세트에 대한 공식 평가 지표는 아직 없지만, 구글은 커뮤니티의 탐구와 추가 연구를 장려하기 위해 기술 보고서에 전체 목록을 포함했습니다.
강력한 멀티모달 기능
트랜스레이트젬마는 젬마 3의 강력한 멀티모달 기능을 그대로 계승합니다. 비스트라(Vistra) 이미지 번역 벤치마크 테스트 결과, 텍스트 번역 성능의 향상이 이미지 내 텍스트 번역 품질에도 긍정적인 영향을 미치는 것으로 나타났습니다. 이는 별도의 멀티모달 미세 조정 없이도 달성한 성과입니다.
어디서나 실행 가능
트랜스레이트젬마는 최신 성능과 탁월한 효율성의 균형을 갖춘 개방형 번역 모델의 새로운 표준을 제시합니다. 세 가지 모델 사이즈는 각기 다른 배포 환경에 최적화되어 있습니다.
- 40억(4B) 모델: 모바일 및 엣지(Edge) 배포에 최적화
- 120억(12B) 모델: 일반 소비자용 노트북에서도 원활히 구동, 로컬 개발 환경에서도 연구용 수준의 성능 제공
- 270억(27B) 모델: 최대의 충실도(fidelity)를 제공하며, 클라우드 상의 단일 H100 GPU 또는 TPU에서 구동 가능
지금 바로 트랜스레이트젬마 사용해 보기
트랜스레이트젬마의 출시는 연구자와 개발자들에게 다양한 번역 작업을 위한 강력하고 유연한 도구를 제공합니다. 구글은 이 모델들이 언어 장벽을 허물고 문화 간 이해를 넓히는 데 어떻게 기여할지 기대가 큽니다. 지금 바로 아래 링크를 통해 사용해 보세요:




