Gemini apre nuove strade: un modello più veloce, contesti più lunghi e agenti AI

A dicembre abbiamo presentato Gemini 1.0, il nostro primo modello nativamente multimodale in tre versioni: Ultra, Pro e Nano. Pochi mesi dopo abbiamo rilasciato 1.5 Pro, con prestazioni migliorate e o una rivoluzionaria finestra di contesto lunga di 1 milione di token.
Gli sviluppatori e i clienti aziendali hanno utilizzato 1.5 Pro in modi incredibili e hanno trovato incredibilmente utili la sua finestra contestuale lunga, le funzionalità di ragionamento multimodali e le impressionanti prestazioni complessive.
Grazie al feedback degli utenti, sappiamo che alcune applicazioni hanno bisogno di una latenza minore e di un costo di servizio più basso. Questo ci ha spinto a continuare a innovare, per cui oggi presentiamo Gemini 1.5 Flash, un modello ancora più leggero di 1.5 Pro, progettato per essere veloce ed efficiente da servire su larga scala.
Sia 1.5 Pro che 1.5 Flash sono disponibili con una finestra contestuale estesa a 1 milione di token in anteprima su Google AI Studio and Vertex AI. Una finestra contestuale a 2 milioni di token è disponibile per gli sviluppatori che usano l’API e i clienti Google Cloud in lista d'attesa. Inoltre, stiamo integrando 1.5 Pro nei Google products, incluso Gemini Advanced e nelle app Workspace.
In aggiunta, annunciamo la nostra prossima generazione di modelli aperti, Gemma 2, e condividiamo gli avanzamenti sul futuro degli assistenti IA, con Project Astra
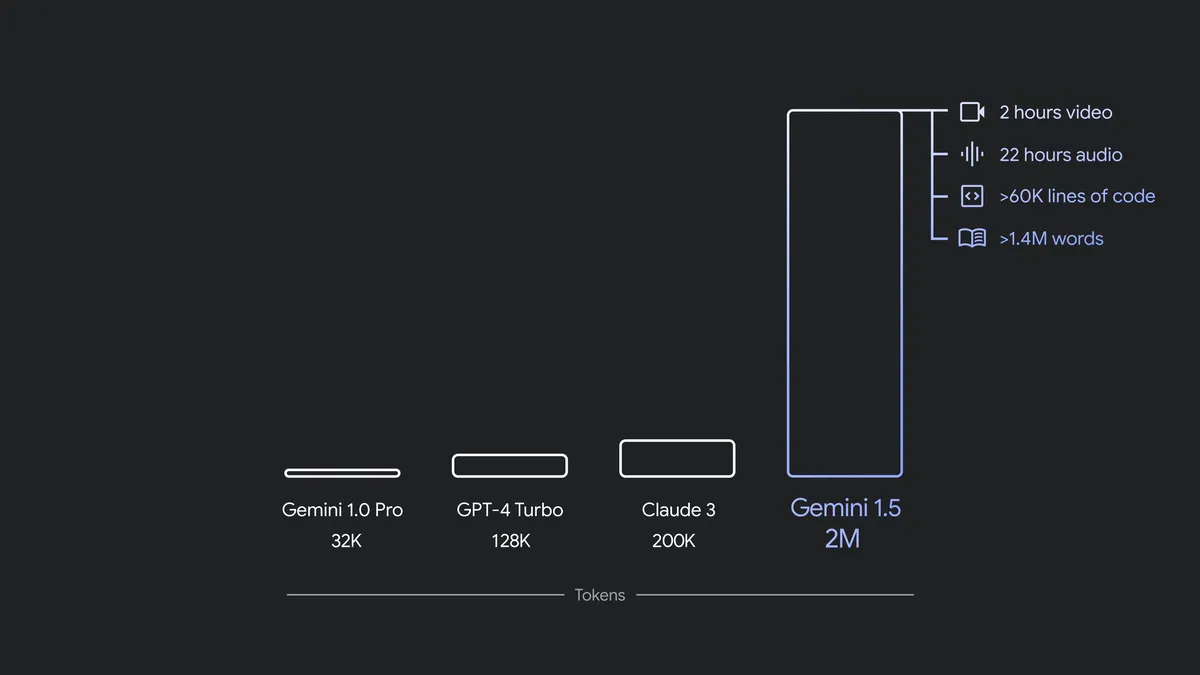
Aggiornamenti sulla famiglia di modelli Gemini
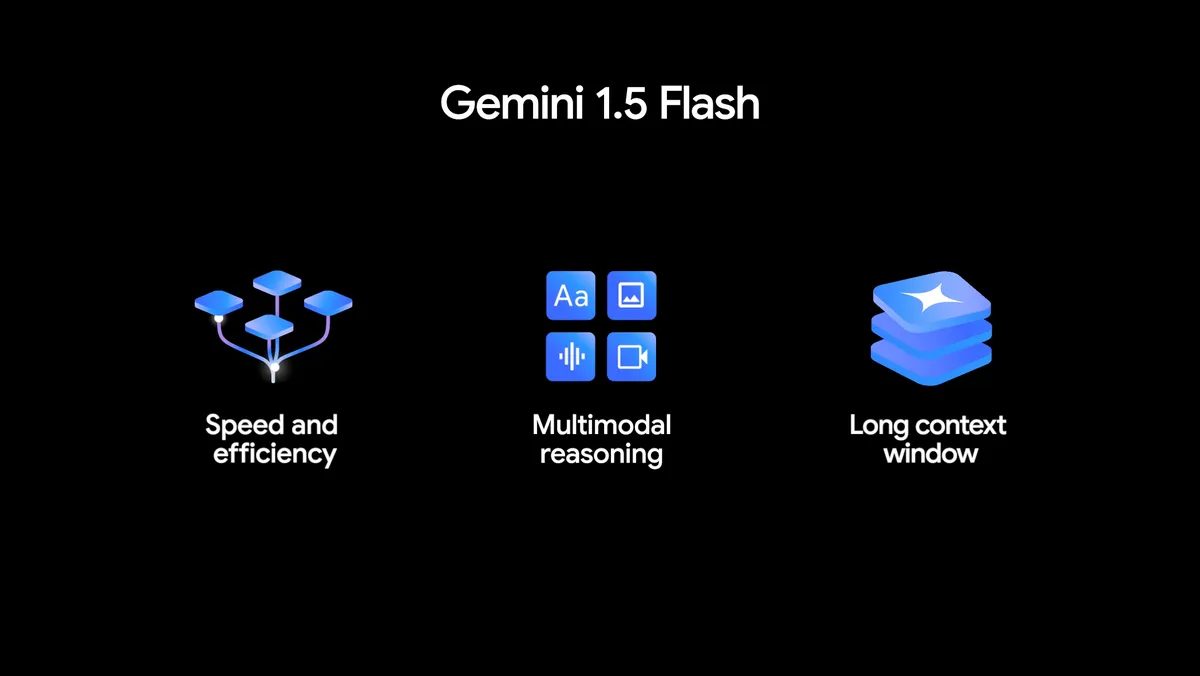
Il nuovo 1.5 Flash, ottimizzato per essere più veloce ed efficiente
1.5 Flash è l’ultimo modello della famiglia Gemini nonché il nostro modello Gemini più veloce disponibile tramite API. È ottimizzato per attività ad alto volume e ad alta frequenza su larga scala, è più conveniente e presenta la nostra rivoluzionaria finestra di contesto lungo.
Anche se meno potente di 1.5 Pro, ha capacità eccellenti di ragionamento multimodale su grandi quantità di informazioni e offre una qualità impressionante per le sue dimensioni.
1.5 Flash eccelle nel riassumere, nelle applicazioni di chat, nei sottotitoli di immagini e video, nell'estrazione di dati da documenti e tabelle lunghi e altro ancora. Questo perché è stato addestrato da 1.5 Pro attraverso un processo chiamato "distillazione", in cui le conoscenze e le competenze più essenziali di un modello più grande vengono trasferite a un modello più piccolo ed efficiente.
Scoprite di più su 1.5 Flash nel report tecnico di Gemini 1.5 aggiornato e sul sito web di Gemini. Disponibilità e prezzi di 1.5 Flash in questo blogpost.
1.5 Pro è ancora più utile
Negli ultimi mesi abbiamo migliorato in modo significativo il nostro modello migliore per la scalabilità in un'ampia gamma di attività. Oltre a estendere la finestra contestuale a 2 milioni di token, abbiamo migliorato la generazione di codice, il ragionamento logico e la pianificazione, la conversazione a turni multipli e la comprensione di audio e immagini.
L'ultima versione di 1.5 Pro ottiene notevoli miglioramenti rispetto ai benchmark pubblici in diversi ambiti, come ragionamento e codifica, nonché prestazioni all'avanguardia su molteplici benchmark di comprensione di immagini e video, tra cui: MMMU, AI2D, MathVista, ChartQA, DocVQA, InfographicVQA e EgoSchema.
Il modello è ora in grado di seguire istruzioni sempre più complesse e articolate, comprese quelle che specificano il comportamento a livello di prodotto, come il ruolo, il formato, lo stile e altro ancora. Abbiamo migliorato il controllo sulle risposte quando si usa il modello per casi d'uso specifici, come creare la personalità e lo stile di risposta di un agente di chat o automatizzare i flussi di lavoro attraverso più chiamate a funzioni.. E abbiamo permesso agli utenti di indirizzare il comportamento del modello impostando istruzioni di sistema.
Abbiamo anche aggiunto la comprensione dell'audio nell'API Gemini e in AI Studio, così 1.5 Pro ora può ragionare su immagini e audio dei video caricati in Google AI Studio.
Maggiori dettagli su 1.5 Pro nel report tecnico di Gemini 1.5 aggiornato e sul sito web di Gemini.
Aggiornamenti di Gemini Nano, il nostro modello on-device
Gemini Nano si sta espandendo oltre gli input di solo testo per includere anche le immagini. A partire da Pixel, le applicazioni che utilizzano Gemini Nano con Multimodalità saranno in grado di comprendere il mondo come fanno le persone, non solo attraverso input di testo, ma anche attraverso la vista, il suono e il linguaggio parlato.
Ulteriori informazioni su Gemini 1.0 Nano su Android.
La nuova generazione di modelli aperti
Oggi condividiamo anche una serie di aggiornamenti su Gemma, la nostra famiglia di modelli aperti costruiti con la stessa ricerca e tecnologia utilizzata per creare i modelli Gemini.
Si tratta di Gemma 2, la nostra nuova generazione di modelli aperti per l'innovazione responsabile dell'intelligenza artificiale. Gemma 2 ha una nuova architettura progettata per prestazioni ed efficienza rivoluzionarie e sarà disponibile in nuove dimensioni.
La famiglia Gemma si espande anche con PaliGemma, il nostro primo modello di linguaggio visivo ispirato a PaLI-3. Inoltre, abbiamo aggiornato il nostro toolkit Responsible Generative AI con il comparatore LLM per valutare la qualità delle risposte del modello.
Maggiori informazioni sul blog degli Sviluppatori.
I nostri progressi nello sviluppo di agenti AI universali
Nell'ambito della missione di Google DeepMind di sviluppare l’intelligenza artificiale in modo responsabile e a servizio delle persone, abbiamo sempre voluto costruire un agente AI universale che potesse essere utile nella quotidianità. Ecco perché oggi condividiamo i passi avanti che abbiamo fatto verso il futuro degli assistenti AI: Project Astra.
Per essere davvero utile, un agente deve capire e rispondere alla complessità e al dinamismo del mondo, proprio come fanno le persone. Inoltre, deve recepire e ricordare ciò che vede per comprendere il contesto e agire. Deve anche essere proattivo, istruibile e personale, in modo che gli utenti possano dialogare con lui in modo naturale e senza ritardi.
Anche se abbiamo fatto passi da gigante nello sviluppo di sistemi di IA in grado di comprendere informazioni multimodali, ridurre i tempi di risposta al livello di una conversazione è una sfida ingegneristica molto difficile. Negli ultimi anni abbiamo lavorato per migliorare il modo in cui i nostri modelli percepiscono, ricordano, ragionano e conversano per rendere più naturale il ritmo e la qualità dell'interazione.
Sulla base del nostro modello Gemini, abbiamo sviluppato agenti sperimentali che elaborano le informazioni più velocemente attraverso la codifica continua di frame, combinando l'input video e vocale in una linea temporale di eventi e memorizzando nella cache queste informazioni per un richiamo efficiente.
Grazie ai nostri modelli vocali principali, abbiamo anche migliorato il modo in cui parlano, per offrendo una gamma più ampia di intonazioni. Ora gli agenti sono in grado di comprendere meglio il contesto in cui vengono utilizzati e di rispondere rapidamente nelle conversazioni.
È facile immaginare un futuro in cui potrete avere un assistente esperto al vostro fianco, utilizzando lo smartphone o gli occhiali. Nel corso dell'anno porteremo alcune di queste capacità agentiche e di visione nei prodotti Google, come l'app Gemini.
Esplorare sempre nuove idee
Abbiamo fatto progressi incredibili con la nostra famiglia di modelli Gemini e cerchiamo sempre di far avanzare ulteriormente lo stato dell’arte. Investendo in una linea di produzione innovativa che non conosce sosta, siamo in grado di esplorare nuove idee all’avanguardia e sbloccare allo stesso tempo la possibilità di nuovi ed entusiasmanti esempi di utilizzo di Gemini.
Scopri di più su Gemini e le sue capacità.





