Gemini Robotics 1.5 を発表、AI エージェントを物理世界に

今年の初め、Gemini Roboticsファミリーモデルを皮切りに、Gemini が持つマルチモーダルな理解力を現実世界へと応用するという進歩を遂げました。
そして本日、インテリジェントで真に汎用的なロボットの実現に向け、高度な思考力に基づき、自律的にタスクを遂行し、エージェント体験を可能にする 2 つの新しいモデルを発表します。
- Gemini Robotics 1.5 は、最も高性能な視覚・言語・行動 (VLA) モデルです。これは、視覚情報と指示を、ロボットがタスクを実行するための具体的な動作命令に変換します。このモデルは、行動を起こす前に思考し、そのプロセスを可視化できます。また、ロボットが複雑なタスクをより透明性の高い形で評価し、完了するのを支援します。また、複数の機体を横断して学習できるため、スキル習得を加速させます。
- Gemini Robotics-ER 1.5 は、最も高性能な視覚・言語モデル (VLM) です。このモデルは、物理世界について推論し、ネイティブにデジタルツールを呼び出し、ミッションを完了するための詳細な多段階の計画を作成します。このモデルは現在、空間理解のベンチマーク全体で最先端のパフォーマンスを達成しています。
これらの進歩は、開発者がより高性能で多用途なロボットを構築するのに役立ちます。これらのロボットは、環境を能動的に理解し、複雑で多段階にわたるタスクを状況に応じて柔軟に完遂できるようになります。
本日より、開発者の皆様は Google AI Studio を通じて Gemini Robotics-ER 1.5 をご利用いただけます。また、Gemini Robotics 1.5 に関しては、現在一部のパートナー企業に提供を開始しています。詳細は Developer Blog をご確認ください。
物理的なタスクのエージェント的な体験を可能に
私たちの身の回りには、状況を読み解き、いくつもの手順を踏んで初めて完了できるタスクが溢れています。こうした複雑な作業は、現代のロボットにとって、依然として非常に困難な課題です。
例えば、「この地域のルールに合わせて、目の前のゴミを分別して」とロボットに頼んだとしましょう。この一見単純な指示を完遂するために、ロボットはまずインターネットで地域の分別ガイドラインを検索し、目の前のゴミが何であるかを認識し、ルールに基づいてそれぞれの分別方法を判断しなければなりません。そして最後に、それらを実際に正しいゴミ箱へ捨てるという一連の行動を、すべて実行する必要があります。このように、複雑で多段階のタスクをロボットが最後までやり遂げられるよう、私たちは2つのモデルが連携して自律的に思考・行動する、新たなフレームワークを設計しました。
エンボディド・リーズニング モデル(身体性推論モデル: 実世界における物理的な状況を理解し推論する能力)であるGemini Robotics-ER 1.5は、ロボット全体の頭脳のように機能し、全ての活動を統括します。このモデルは、物理世界の状況を的確に把握する最先端の空間認識能力を活かし、論理的な意思決定と計画立案に優れています。人間と自然な言葉で対話し、タスクの成功率や進捗を予測するだけでなく、必要に応じてGoogle 検索のようなツールで情報を集めたりサードパーティのユーザー定義関数を使用したりすることができます。
そして、Gemini Robotics-ER 1.5 は導き出した計画をステップごとに自然言語の指示に変換し、Gemini Robotics 1.5 へと伝えます。指示を受けたGemini Robotics 1.5 は、その優れた視覚と言語の理解能力を用いて、具体的なアクションを直接実行します。さらにこのモデルは、自らの行動について思考することで、意味が複雑なタスクをより巧みに解決するだけでなく、その思考プロセスを人間に言葉で説明することもできます。これにより、ロボットの意思決定の透明性が高まります。
物理世界における複雑なタスクを遂行するために、Gemini Robotics-ER 1.5 と Gemini Robotics 1.5 の 2 つのモデルが、いかに連携して機能するかを示した図
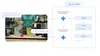
これら両モデルは、中核となるGeminiモデルファミリーを基盤としており、それぞれの役割に特化するよう異なるデータセットでファインチューニングされています。これらを連携させることで、ロボットがより長いタスクや多様な環境に汎化する能力が高まります。
現実世界への理解力
Gemini Robotics-ER 1.5は、エンボディド推論に特化して最適化された、初めての思考モデルです。テスターの皆様にご協力いただくプログラムを通じて、現実世界の様々なユースケースを反映させて開発されました。その結果、学術的なベンチマークと社内の独自ベンチマークの両方において、最先端のパフォーマンスを達成します。
このモデルの性能を検証するため、Embodied Reasoning Question Answering (ERQA) やPoint-Bench をはじめとする 15 の学術的ベンチマークを用いた評価を実施し、ポインティング(指示)、画像やビデオの内容に関する質疑応答といった能力を測定しました。
詳細は技術レポートをご確認ください。
類似モデルと比較した、Gemini Robotics-ER 1.5 の最先端のパフォーマンス結果を示す棒グラフ。当社のモデルは、Point-Bench、RefSpatial、RoboSpatial-Pointing、Where2Place、BLINK、CV-Bench、ERQA、EmbSpatial、MindCube、RoboSpatial-VQA、SAT、Cosmos-Reason1、Min Video Pairs、OpenEQA、VSI-Benchなど、15 の学術的な身体性推論のベンチマークにおいて、最高の集計パフォーマンスを達成しています。

Gemini Robotics-ER 1.5 の物体検出、状態推定、セグメンテーションマスク、ポインティング、軌道予測、タスクの進捗と成功の推定などの能力。

行動を起こす前に自ら思考
従来の視覚・言語・行動モデルは、与えられた指示や計画を、そのままロボットの動きに直接的に変換するだけでした。それに対し、Gemini Robotics 1.5 は、単に指示を変換するだけでなく、行動を起こす前に自ら思考することができます。つまり、複数の手順や深い意味の理解が求められるタスクに対し、まず自然言語で内的な推論と分析、つまり思考プロセスを組み立て、その上で行動に移します。
例えば、「洗濯物を色分けして」というタスクを与えられた場合、ロボットは異なるレベルで思考します。まず、「色分け」とは白い服は白いカゴへ、それ以外の色の服は黒いカゴへ入れることだと、タスク全体の目的を理解します。次に、「赤いセーターを拾い上げ、黒いカゴに入れる」といった具体的なステップを考え、さらには「セーターを掴みやすくするために、一度手前に引き寄せる」など、各ステップを実行するための細かな動作レベルまで考えます。
この多層的な思考プロセスを通じて、視覚・言語・行動モデルは、より長いタスクを、ロボットが確実に実行できるような、よりシンプルで短い単位へと分解することを自ら判断します。さらに、こうした能力は、モデルが未知のタスクに対応する能力や、周囲の環境変化に対する堅牢性を高める上でも重要な役割を果たします。
異なる機体に対応
ロボットは形状、サイズ、センサー、関節の自由度などが一体一体すべて異なるため、あるロボットで学習したスキルを別のロボットに応用することは、これまで大きな課題でした。
Gemini Robotics 1.5は、異なる機体(エンボディメント)を横断して学習する顕著な能力を有します。新しい機体ごとにモデルを特化させる必要なく、あるロボットで学習した動きを別のロボットに移転できます。この飛躍的な進化は、ロボットが新しいスキルを習得するスピードを加速させ、その知性と実用性をさらに高いレベルへと引き上げます。
実際に、トレーニングでは ALOHA 2 ロボットにのみ提示されたタスクが、Apptronik社のヒューマノイドロボットApollo や Franka ロボットでもそのまま機能すること、そしてその逆も同様であることを観測しています。
AIとロボット工学の責任ある発展のための取り組み
エンボディド AI が持つ大きな可能性を解き放つと同時に、私たちは安全性の確保を最優先事項として捉えています。自ら思考し行動する エージェントAI としてのロボットが、人間中心の社会で責任ある形で活用される未来を見据え、私たちは安全性とアライメントに関する新たなアプローチを積極的に開発しています。
この取り組みを確かなものにするため、専門組織であるResponsibility & Safety Council (RSC) や Responsible Development & Innovation (ReDI) チームがロボティクスチームと緊密に連携し、開発されるすべてのモデルが Google のAI 原則を遵守するよう徹底しています。
Gemini Robotics 1.5は、高度な意味論的推論を通じて、安全性への多角的なアプローチを実装しています。具体的には、行動を起こす前にまず安全性を自ら思考すること、GoogleのGemini Safety Policies に準拠し人間との敬意ある対話を保つこと、そして必要に応じて衝突回避などの物理的な安全サブシステムを作動させることなどが含まれます。
Gemini Roboticsモデルの安全な開発をさらに推進するため、ASIMOV ベンチマークのアップグレード版を公開します。これは、AIの意味論的安全性を評価・改善するために設計された包括的なデータセットです。今回のアップグレードでは、テールカバレッジの向上、アノテーションの改善、新たなタイプの安全性に関する質問、そしてビデオフォーマットへの対応などが含まれています。
この最新のASIMOV ベンチマークを用いた安全性評価において、Gemini Robotics-ER 1.5は最先端のパフォーマンスを達成しました。特に、思考能力において、意味論的安全性の深い理解や、物理的な安全上の制約をより厳格に遵守する上で、大きく貢献しています。
物理世界における AGI の実現に向けた一歩
Gemini Robotics 1.5 は、物理世界における AGI の実現に向けた一歩です。単にコマンドに反応するだけのモデルから、自ら推論し、計画を立て、ツールを使いこなし、そして未知の状況にも対応(汎化)する自律的なシステムの構築を目指します。
これは、ロボットが知性と器用さを兼ね備え、物理世界の複雑さを乗り越え、最終的には私たちの生活においてより役立ち、統合された存在となるロボットを構築するための基礎的な一歩です。
私たちは、広範な研究コミュニティの皆様と共にこの探求を続けられることを大変嬉しく思います。そして、ロボティクス コミュニティにいる皆様が、最新の Gemini Robotics-ERモデルを使ってどのような未来を創造するのか、心から楽しみにしています。