제미나이 로보틱스 1.5로 AI 에이전트를 물리적 세계로 가져오다

올해 초, 구글은 제미나이의 멀티모달 이해 능력을 실제 물리적 세계로 확장하는데 놀라운 진전을 이루었습니다. 그리고 그 출발점에는 바로 제미나이 로보틱스(Gemini Robotics) 모델군이 있었습니다.
오늘, 구글은 지능적이면서도 범용적인 로봇 개발을 향해 또 한 걸음을 내딛기 위해, 고도화된 추론 능력을 바탕으로 에이전트 경험(agentic experience)을 선보이는 두 가지 제미나이 로보틱스 모델을 새롭게 소개합니다.
- 제미나이 로보틱스 1.5 – 구글의 가장 강력한 VLA(Vision-Language-Action) 모델로, 시각 정보를 이해하고 지시를 받아 이를 로봇의 동작 명령으로 변환합니다. 단순히 지시에 반응하는 것이 아니라, 행동에 앞서 사고 과정을 드러내며 복잡한 작업을 더 투명하게 평가하고 수행할 수 있도록 돕습니다. 또한 다양한 형태의 로봇에서 학습하며, 기술 습득 속도를 가속화합니다.
- 제미나이 로보틱스-ER 1.5 – 구글의 가장 정교한 VLM(Vision-Language Model)으로, 물리적 세계에 대해 추론하고, 디지털 툴을 직접 호출하며, 세부적인 다단계 실행 계획을 수립합니다. 이 모델은 공간 이해 벤치마크에서 최첨단 성능을 달성하며, 로봇의 임무 수행 능력을 새로운 수준으로 끌어올립니다.
이러한 기술 혁신을 통해 개발자들은 주변 환경을 더 능동적으로 이해하고, 복잡한 다단계 작업을 범용적으로 수행할 수 있는 한층 더 강력하고 다재다능한 로봇을 구축할 수 있게 됩니다.
오늘부터 개발자들은 구글 AI 스튜디오(Google AI Studio)의 제미나이 API를 통해 제미나이 로보틱스-ER 1.5를 사용할 수 있습니다. 현재 제미나이 로보틱스 1.5는 일부 파트너에게만 우선 제공되고 있습니다. 차세대 물리적 에이전트 구축에 대해 더 자세히 알고 싶다면, 개발자 블로그에서 확인해 보시기 바랍니다.
제미나이 로보틱스 1.5: 물리적 작업을 위한 에이전트 경험의 확장
대부분의 일상적인 작업은 맥락적 정보와 여러 작업 단계를 필요로 하기 때문에, 오늘날 로봇에게는 특히 도전적인 과제입니다.
예를 들어 로봇에게 “내 위치를 기준으로 이 물건들을 음식물, 재활용, 일반 쓰레기통으로 각각 올바르게 분류해 줄래?"라고 요청한다고 가정해 보겠습니다. 로봇이 이 요청을 수행하려면, 먼저 인터넷에서 지역별 분리수거 및 쓰레기 처리 가이드를 검색하고, 눈 앞의 물건들을 확인한 뒤, 그 가이드에 맞춰 분류하며, 마지막으로 분류된 물건을 올바른 통에 넣는 일련의 과정을 수행합니다. 이처럼 복잡한 다단계의 작업을 처리할 수 있도록, 구글은 에이전트 프레임워크(agentic framework) 내에서 함께 작동하는 두 가지 모델을 설계했습니다.
구글의 구체화된 추론 모델(embodied reasoning model)인 제미나이 로보틱스-ER 1.5 모델은 마치 로봇의 활동을 총괄하는 ‘고차원적 두뇌’와 같습니다. 물리적 환경에서의 계획 수립과 논리적 의사결정에 강점을 갖고 있으며, 공간 이해 능력에서 뛰어난 성능을 자랑합니다. 또한 자연어로 상호작용할 수 있고, 성공 가능성과 진행 상황을 측정하며, 구글 검색(Google Search)과 같은 툴을 직접 활용하거나 이용자가 정의한 서드파티(third-party) 기능까지 사용할 수 있습니다.
그 다음 제미나이 로보틱스-ER 1.5 모델이 제미나이 로보틱스 1.5 모델에게 각 단계에 대해 자연어로 지시합니다. 그러면 제미나이 로보틱스 1.5 모델은 시각 및 언어 이해 능력을 바탕으로 구체적인 동작을 실행합니다. 단순히 지시에 따라 움직이는 것에 그치지 않고, 행동을 스스로 사고하며 의미적으로 복잡한 과제를 해결할 수 있습니다. 더 나아가 자신의 사고 과정을 자연어로 설명해, 의사결정 과정을 더욱 투명하게 보여줄 수 있습니다.
구글의 구체화된 추론 모델 ‘제미나이 로보틱스-ER 1.5’와 VLA 모델 ‘제미나이 로보틱스 1.5’가 어떻게 상호 보완적으로 작동하고 실제 물리적 세계에서 복잡한 작업을 수행하는지를 보여주는 다이어그램
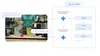
구글의 구체화된 추론 모델 ‘제미나이 로보틱스-ER 1.5’와 VLA 모델 ‘제미나이 로보틱스 1.5’가 어떻게 상호 보완적으로 작동하고 실제 물리적 세계에서 복잡한 작업을 수행하는지를 보여주는 다이어그램
두 모델은 모두 제미나이 모델 제품군을 기반으로 구축되었으며, 각각의 역할에 특화될 수 있도록 서로 다른 데이터셋으로 정밀하게 학습되었습니다. 이 두 모델이 결합되면, 더 긴 작업을 일반화하고 더 다양한 환경에 적응할 수 있는 로봇의 능력이 크게 향상됩니다.
주변 환경을 이해하는 로봇
제미나이 로보틱스-ER 1.5는 구체화된 추론(embodied reasoning)에 최적화된 최초의 사고 기반 모델로, 학계 및 내부 벤치마크에서 모두 최첨단 성능(state-of-the-art performance)을 달성했습니다. 이 모델은 구글의 신뢰받는 테스터 프로그램(Trusted Tester Program)에서 얻은 실제 활용 사례에서 영감을 받아 검증된 결과를 바탕으로 설계되었습니다.
구글은 제미나이 로보틱스-ER 1.5를 ERQA(Embodied Reasoning Question Answering) 및 Point-Bench를 포함한 15개의 학술 벤치마크에서 평가했으며, 지시 동작(pointing), 이미지 기반 질의응답, 비디오 기반 질의응답 등 다양한 영역에서 성능을 측정했습니다.
자세한 내용은 구글 기술 보고서에서 확인할 수 있습니다.
막대그래프: 제미나이 로보틱스-ER 1.5의 최첨단 성능을 유사 모델들과 비교한 결과, Point-Bench, RefSpatial, RoboSpatial-Pointing, Where2Place, BLINK, CV-Bench, ERQA, EmbSpatial, MindCube, RoboSpatial-VQA, SAT, Cosmos-Reason1, Min Video Pairs, OpenEQA, VSI-Bench를 포함한 15개 학술적인 구체화된 추론 벤치마크에서 종합 성능 최고치를 달성했습니다.

GIF 콜라주: 제미나이 로보틱스-ER 1.5의 다양한 기능 시연 — 객체 인식 및 상태 추정(object detection and state estimation), 분할 마스크(segmentation mask), 포인팅, 궤적 예측, 작업 진행 상황 및 성공 여부 판별 등
행동에 앞서 ‘생각하는’ 로봇
기존의 VLA 모델은 주어진 지시나 언어적 계획을 그대로 로봇의 움직임으로 전환하는 방식이었다면, 제미나이 로보틱스 1.5는 단순한 변환을 넘어, 행동에 앞서 사고할 수 있습니다. 즉, 여러 단계가 필요한 작업이나 더 깊은 의미 이해가 필요한 상황에서, 자연어 기반의 내적 추론 과정과 분석 단계를 스스로 생성하여 작업을 수행할 수 있음을 의미합니다.
예를 들어, “세탁물을 색깔별로 분류해 줘”라는 요청을 수행할 때, 로봇은 다양한 수준에서 사고합니다. 먼저, 색깔별 분류란 흰 옷은 흰색 통에, 그 외 색상은 검은색 통에 넣는 것임을 이해합니다. 그다음, 빨간 스웨터를 들어 검은색 통에 넣는 단계별 행동을 계획하고, 실제로 스웨터를 더 쉽게 집을 수 있도록 옮기는 세부 동작까지 생각해 냅니다.
이러한 다단계 사고 과정을 거치면서, VLA 모델은 긴 작업을 로봇이 성공적으로 실행할 수 있는 더 단순한 짧은 단계들로 나눌 수 있습니다. 이는 모델이 새로운 작업을 일반화하여 해결하는 데 도움을 주고, 환경 변화에도 보다 강인하게 대응할 수 있도록 합니다.
다양한 형태를 넘어 학습하는 로봇
로봇은 형태와 크기, 감지 능력, 자유도가 제각각이어서, 한 로봇이 배운 동작을 다른 로봇에 그대로 옮기는 것은 매우 어려웠습니다.
그러나 제미나이 로보틱스 1.5는 서로 다른 로봇 간에도 학습한 동작을 전이할 수 있는 놀라운 능력을 보여줍니다. 새로운 로봇마다 모델을 개별적으로 특화할 필요 없이, 한 로봇에서 학습한 동작을 다른 로봇에서도 그대로 수행할 수 있습니다. 이 획기적인 진전은 새로운 행동 학습 속도를 크게 높여, 로봇이 더욱 똑똑하고 유용하게 진화하는 데 기여합니다.
예를 들어, 학습 과정에서 ALOHA 2 로봇에게만 주어진 작업이, Apptronik의 휴머노이드 로봇 Apollo나 양팔 로봇 Franka에서도 그대로 작동하는 것을 확인할 수 있습니다. 그 반대의 경우도 마찬가지입니다.
AI와 로보틱스를 책임감 있게 발전시키는 방법
구글은 구체화된 AI(embodied AI)의 잠재력을 최대한 이끌어내는 동시에, 인간 중심 환경에서 에이전트 AI 로봇이 안전하게 활용될 수 있도록 새로운 안전 및 정렬 접근법을 선제적으로 개발하고 있습니다.
이를 위해 ‘책임 및 안전 위원회(Responsibility & Safety Council, RSC)’와 ‘책임 있는 개발 및 혁신팀(Responsible Development & Innovation, ReDI)’이 로보틱스 팀과 협력해, 모델 개발이 구글의 ‘AI 원칙(AI Principles)’에 부합하도록 지속적으로 점검하고 있습니다.
제미나이 로보틱스 1.5는 안전을 위해 총체적 접근을 적용합니다. 구체적으로는 행동에 앞서 안전을 먼저 사고하는 고차원 의미론적 추론, 기존 제미나이 안전 정책(Gemini Safety Policies)에 따른 사람과의 존중 있는 대화, 필요할 경우 로봇에 내장된 저수준 안전 시스템(예: 충돌 회피)까지 가동해 안전을 보장합니다.
또한 제미나이 로보틱스 모델의 안전한 개발을 이끌기 위해, 구글은 ASIMOV 벤치마크의 업그레이드 버전을 공개합니다. 이 벤치마크는 의미론적 안전성을 평가 및 개선하기 위한 포괄적 데이터셋 모음으로, 더욱 폭넓은 시나리오, 개선된 주석, 새로운 안전 질문 유형과 비디오 모달리티를 포함합니다.
ASIMOV 벤치마크 기반의 안전 평가에서 제미나이 로보틱스-ER 1.5는 최고 수준의 성능을 보여주었으며, 특히 모델의 사고 능력 의미론적 안전성에 대한 이해와 물리적 안전 제약 준수 능력을 크게 향상시키는 것으로 확인되었습니다.
구글의 안전 연구에 대해 더 알아보려면 구글의 기술 보고서 또는 안전 관련 웹사이트를 방문해 주세요.
물리적 세계에서 AGI 를 실현해 나가는 이정표
제미나이 로보틱스 1.5는 물리적 세계에서 AGI(범용 인공지능)를 실현해 나가는 여정의 중요한 이정표입니다. 단순히 명령에 반응하는 수준을 넘어, 사고, 계획, 일반화까지 가능한 에이전트형 능력을 도입함으로써, 구글은 로봇의 새로운 가능성을 열고 있습니다.
이는 지능과 기민함을 바탕으로 물리적 세계의 복잡성을 탐색하고, 궁극적으로는 우리 삶 속에서 더 유용하고 자연스럽게 통합되는 로봇을 구축하기 위한 기초적 단계입니다.
구글은 이 연구를 더 넓은 연구 커뮤니티와 함께 이어가기를 기대하며, 최신 제미나이 로보틱스 모델을 통해 연구자와 개발자들이 어떤 혁신을 만들어갈지 무척 기대하고 있습니다.




