Ironwood:首款適用於 AI 推論時代的 Google TPU


今天在 Google Cloud Next 25 大會上,我們隆重推出第 7 代 Tensor Processing Unit(TPU)— Ironwood。這不僅我們迄今效能最高、擴展性最佳的客製化 AI 加速器,更是第一款專為推論而設計的 TPU。十多年來,TPU 一直為 Google 最嚴苛的 AI 訓練與執行工作負載提供支援,並助力我們的雲端客戶實現相同目標。Ironwood 是我們至今最強大、功能最全面且能源效率最高的 TPU,專為大規模驅動思考型(thinking)、推論型(inferential)的 AI 模型而打造。
Ironwood 的問世,代表著 AI 發展及其底層基礎架構演進的的一大轉變。從為人們提供即時資訊以供解讀的回應式 AI (responsive AI)模型,轉向能夠主動生成洞察和解讀的模型。這就是我們所說的「推論時代」(age of inference),在此時代,AI 代理將主動擷取和生成資料,以協同方式提供洞察與解答,而不僅僅是提供資料。
Ironwood 的建構是為了支援生成式 AI 的下一個發展階段及其龐大的運算和通訊需求。Ironwood 可以擴展到高達 9,216 顆液冷晶片(liquid cooled chips),這些晶片透過突破性的晶片間互連(Inter-Chip Interconnect, ICI)網路相連。它是 Google Cloud AI Hypercomputer 架構的多項新元件之一,該架構旨在硬體與軟體層面進行整合優化,以因應最嚴苛的 AI 工作負載。透過 Ironwood,開發者還能利用 Google 自家的 Pathways 軟體堆疊,可靠且輕鬆地利用數萬個 Ironwood TPU 的組合運算能力。
以下我們將深入探討這些創新如何協同運作,以無與倫比的效能、成本效益和能源效率來處理最嚴苛的訓練與執行工作負載。
以 Ironwood 驅動推論時代
Ironwood 的設計旨在從容應對「思考模型」的複雜運算和通訊需求,這類模型涵蓋了大型語言模型(LLMs)、專家混和模型(Mixture of Experts, MoEs)和進階推理任務。這些模型需要大規模的平行處理能力和高效的記憶體存取,而 Ironwood 的設計正是著重於執行大量張量運算的同時,最大限度地降低晶片上的資料搬移和延遲。在前沿應用方面,思考模型的運算需求遠遠超出任何單一晶片的處理容量。我們為 Ironwood TPU 設計了低延遲、高頻寬的 ICI 網路,以支援在整個 TPU Pod 規模下進行協調且同步的通訊。
針對 Google Cloud 客戶,Ironwood 根據 AI 工作負載的需提供兩種規模配置:256 顆晶片配置和 9,216 顆晶片配置。
- 當擴展到每個 Pod 達 9,216 顆晶片時,總運算能力可達 4,250 萬兆次浮點運算(42.5 Exaflops),是世界上最大的超級電腦 El Capitan 的 24 倍以上,後者每個 Pod 僅提供 170 萬兆次浮點運算(1.7 Exaflos)。Ironwood 提供的大規模平行運算能力,能夠支援最嚴苛的 AI 工作負載,例如用於訓練和推理、具備思考能力的超大型密集 LLM 或 MoE 模型。每顆獨立晶片的峰值運算能力高達每秒 4,614 兆次浮點運算(4,614 TFLOPs),代表著 AI 能力的飛躍進步。此外,Ironwood 的記憶體和網路架構確保了在如此龐大的規模下,始終能夠提供正確的資料可支援峰值效能。
- Ironwood 還配備了增強版的 SparseCore,這是一種專門用於處理進階排序和推薦系統工作負載中常見的超大規模嵌入(embeddings)的加速器。Ironwood 中擴展的 SparseCore 支援允許加速更廣泛的工作負載,甚至跨越傳統 AI 領域,進入金融和科學等領域。
- Google DeepMind 開發的機器學習執行階段架構 Pathways,能在多個 TPU 晶片間實現高效的分散式運算。Google Cloud 上的 Pathways 讓使用者能輕易超越單個 Ironwood Pod 的限制,將數十萬顆 Ironwood 晶片組合在一起,以快速推進生成式 AI 運算的前沿發展。
圖一:相較於 Google 首款對外提供的 Cloud TPU v2, FP8 總峰值浮點運算效能提升幅度。
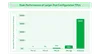
圖二:包括最新一代 Ironwood 在內的 Cloud TPU 產品(3D 環形網路版本,3D torus version)技術規格並列比較。FP8 峰值 TFlops 在 v4 與 v5p 上為模擬達成,Ironwood 則提供原生支援。

Ironwood 的主要功能
Google Cloud 是唯一一家擁有超過十年提供 AI 運算經驗的超大規模雲端供應商,不僅支援尖端研究,更將這些技術無縫整合到全球規模等級的服務中,每天為數十億使用者提供 Gmail、Google 搜尋等服務。這些專業知識正是 Ironwood 效能的核心所在。主要功能包括:
- 在效能大幅提升的同時,也注重於能源效率,使 AI 工作負載能夠以更符合成本效益的方式運行。相較於 2024 年推出的第 6 代 TPU Trillium,Ironwood 的效能功耗比是 Trillium 的 2 倍。在當前可用電力成為 AI 發展限制因素之一的時代,我們為客戶的工作負載提供了每瓦更多的運算能力。我們先進的液冷解決方案和優化的晶片設計,即使在面對持續繁重的 AI 工作負載之下,也能可靠地維持較標準氣冷高出近兩倍的效能。事實上,Ironwood 的能源效率較我們 2018 年推出的首款 Cloud TPU 提升近 30 倍。
- 大幅增加高頻寬記憶體(HBM)容量。Ironwood 每顆晶片提供 192 GB 容量,是 Trillium 的 6 倍,能處理更大型的模型和資料集運算,減少頻繁的資料傳輸需求,進而提升整體效能。
- HBM 頻寬大幅提升,單顆晶片可達 7.2 Tbps,是 Trillium 的 4.5 倍。如此高速的頻寬能確保資料快速存取,這對於現代 AI 中常見的記憶體密集型工作負載而言至關重要。
- 增強晶片間互連(ICI)頻寬。雙向傳輸已提高到 1.2 Tbps,是 Trillium 的 1.5 倍,能加速晶片間的通訊,有助於提升大型分散式訓練和推論的效率。
圖三:相較於最早的 Cloud TPU v2,Google TPU 的能源效率有顯著提升。此數據是以每顆晶片封裝在熱設計功耗(TDP)下所能達到的 FP8 峰值運算效能(flops per watt)進行衡量。

Ironwood 滿足了未來 AI 的需求
Ironwood 憑藉其全面提升的運算能力、記憶體容量、晶片互連技術進展與可靠性,代表推論時代的一項獨特關鍵突破。這些突破,加上近 2 倍的能源效率提升,意味著我們需求最高的客戶能以最高的效能與最低的延遲來處理訓練與推論執行工作負載,同時滿足暴增的運算需求。當前尖端 AI 模型如 Gemini 2.5 和榮獲諾貝爾獎的 AlphaFold, 如今都在 TPU 上運行。我們迫不及待地想看,當今年稍晚推出 Ironwood 時,我們自家的開發人員和 Google Cloud 客戶將會激盪出哪些 AI 重大突破。