How Google autocomplete predictions are generated

You come to Google with an idea of what you’d like to search for. As soon as you start typing, predictions appear in the search box to help you finish what you’re typing. These time-saving predictions are from a feature called Autocomplete, which we covered previously in this How Search Works series.
In this post, we’ll explore how Autocomplete’s predictions are automatically generated based on real searches and how this feature helps you finish typing the query you already had in mind. We’ll also look at why not all predictions are helpful, and what we do in those cases.
Where predictions come from
Autocomplete predictions reflect searches that have been done on Google. To determine what predictions to show, our systems begin by looking at common and trending queries that match what someone starts to enter into the search box. For instance, if you were to type in “best star trek…”, we’d look for the common completions that would follow, such as “best star trek series” or “best star trek episodes.”
That’s how predictions work at the most basic level. However, there’s much more involved. We don’t just show the most common predictions overall. We also consider things like the language of the searcher or where they are searching from, because these make predictions far more relevant.
Below, you can see predictions for those searching for “driving test” in the U.S. state of California versus the Canadian province of Ontario. Predictions differ in naming relevant locations or even spelling “centre” correctly for Canadians rather than using the American spelling of “center.”

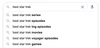
To provide better predictions for long queries, our systems may automatically shift from predicting an entire search to portions of a search. For example, we might not see a lot of queries for “the name of the thing at the front” of some particular object. But we do see a lot of queries for “the front of a ship” or “the front of a boat” or “the front of a car.” That’s why we’re able to offer these predictions toward the end of what someone is typing.
We also take freshness into account when displaying predictions. If our automated systems detect there’s rising interest in a topic, they might show a trending prediction even if it isn’t typically the most common of all related predictions that we know about. For example, searches for a basketball team are probably more common than individual games. However, if that team just won a big face-off against a rival, timely game-related predictions may be more useful for those seeking information that’s relevant in that moment.
Predictions also will vary, of course, depending on the specific topic that someone is searching for. People, places and things all have different attributes that people are interested in. For example, someone searching for “trip to New York” might see a prediction of “trip to New York for Christmas,” as that’s a popular time to visit that city. In contrast, “trip to San Francisco” may show a prediction of “trip to San Francisco and Yosemite.” Even if two topics seem to be similar or fall into similar categories, you won’t always see the same predictions if you try to compare them. Predictions will reflect the queries that are unique and relevant to a particular topic.
Overall, Autocomplete is a complex time-saving feature that’s not simply displaying the most common queries on a given topic. That’s also why it differs from and shouldn’t be compared against Google Trends, which is a tool for journalists and anyone else who’s interested to research the popularity of searches and search topics over time.
Predictions you likely won’t see
Predictions, as explained, are meant to be helpful ways for you to more quickly finish completing something you were about to type. But like anything, predictions aren’t perfect. There’s the potential to show unexpected or shocking predictions. It’s also possible that people might take predictions as assertions of facts or opinions. We also recognize that some queries are less likely to lead to reliable content.
We deal with these potential issues in two ways. First and foremost, we have systems designed to prevent potentially unhelpful and policy-violating predictions from appearing. Secondly, if our automated systems don’t catch predictions that violate our policies, we have enforcement teams that remove predictions in accordance with those policies.
Our systems are designed to recognize terms and phrases that might be violent, sexually-explicit, hateful, disparaging or dangerous. When we recognize that such content might surface in a particular prediction, our systems prevent it from displaying.
People can still search for such topics using those words, of course. Nothing prevents that. We’re simply not wanting to unintentionally shock or surprise people with predictions they might not have expected.
Using our automated systems, we can also recognize if a prediction is unlikely to return much reliable content. For example, after a major news event, there can be any number of unconfirmed rumors or information spreading, which we would not want people to think Autocomplete is somehow confirming. In these cases, our systems identify if there’s likely to be reliable content on a particular topic for a particular search. If that likelihood is low, the systems might automatically prevent a prediction from appearing. But again, this doesn’t stop anyone from completing a search on their own, if they wish.
While our automated systems typically work very well, they don’t catch everything. This is why we have policies for Autocomplete, which we publish for anyone to read. Our systems aim to prevent policy-violating predictions from appearing. But if any such predictions do get past our systems, and we’re made aware (such as through public reporting options), our enforcement teams work to review and remove them, as appropriate. In these cases, we remove both the specific prediction in question and often use pattern-matching and other methods to catch closely-related variations.
As an example of all this in action, consider our policy about names in Autocomplete, which began in 2016. It’s designed to prevent showing offensive, hurtful or inappropriate queries in relation to named individuals, so that people aren’t potentially forming an impression about others solely off predictions. We have systems that aim to prevent these types of predictions from showing for name queries. But if violations do get through, we remove them in line with our policies.
You can always search for what you want
Having discussed why some predictions might not appear, it’s also helpful to remember that predictions are not search results. Occasionally, people concerned about predictions for a particular query might suggest that we’re preventing actual search results from appearing. This is not the case. Autocomplete policies only apply to predictions. They do not apply to search results.
We understand that our protective systems may prevent some useful predictions from showing. In fact, our systems take a particularly cautious approach when it comes to names and might prevent some non-policy violating predictions from appearing. However, we feel that taking this cautious approach is best. That’s especially because even if a prediction doesn’t appear, this does not impact the ability for someone to finish typing a query on their own and finding search results.
We hope this has helped you understand more about how we generate predictions that allow you to more quickly complete the query you started, whether that’s while typing on your laptop or swiping the on-screen keyboard on your phone.