Understanding searches better than ever before

If there’s one thing I’ve learned over the 15 years working on Google Search, it’s that people’s curiosity is endless. We see billions of searches every day, and 15 percent of those queries are ones we haven’t seen before--so we’ve built ways to return results for queries we can’t anticipate.
When people like you or I come to Search, we aren’t always quite sure about the best way to formulate a query. We might not know the right words to use, or how to spell something, because often times, we come to Search looking to learn--we don’t necessarily have the knowledge to begin with.
At its core, Search is about understanding language. It’s our job to figure out what you’re searching for and surface helpful information from the web, no matter how you spell or combine the words in your query. While we’ve continued to improve our language understanding capabilities over the years, we sometimes still don’t quite get it right, particularly with complex or conversational queries. In fact, that’s one of the reasons why people often use “keyword-ese,” typing strings of words that they think we’ll understand, but aren’t actually how they’d naturally ask a question.
With the latest advancements from our research team in the science of language understanding--made possible by machine learning--we’re making a significant improvement to how we understand queries, representing the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search.
Applying BERT models to Search
Last year, we introduced and open-sourced a neural network-based technique for natural language processing (NLP) pre-training called Bidirectional Encoder Representations from Transformers, or as we call it--BERT, for short. This technology enables anyone to train their own state-of-the-art question answering system.
This breakthrough was the result of Google research on transformers: models that process words in relation to all the other words in a sentence, rather than one-by-one in order. BERT models can therefore consider the full context of a word by looking at the words that come before and after it—particularly useful for understanding the intent behind search queries.
But it’s not just advancements in software that can make this possible: we needed new hardware too. Some of the models we can build with BERT are so complex that they push the limits of what we can do using traditional hardware, so for the first time we’re using the latest Cloud TPUs to serve search results and get you more relevant information quickly.
Cracking your queries
So that’s a lot of technical details, but what does it all mean for you? Well, by applying BERT models to both ranking and featured snippets in Search, we’re able to do a much better job helping you find useful information. In fact, when it comes to ranking results, BERT will help Search better understand one in 10 searches in the U.S. in English, and we’ll bring this to more languages and locales over time.
Particularly for longer, more conversational queries, or searches where prepositions like “for” and “to” matter a lot to the meaning, Search will be able to understand the context of the words in your query. You can search in a way that feels natural for you.
To launch these improvements, we did a lot of testing to ensure that the changes actually are more helpful. Here are some of the examples that showed up our evaluation process that demonstrate BERT’s ability to understand the intent behind your search.
Here’s a search for “2019 brazil traveler to usa need a visa.” The word “to” and its relationship to the other words in the query are particularly important to understanding the meaning. It’s about a Brazilian traveling to the U.S., and not the other way around. Previously, our algorithms wouldn't understand the importance of this connection, and we returned results about U.S. citizens traveling to Brazil. With BERT, Search is able to grasp this nuance and know that the very common word “to” actually matters a lot here, and we can provide a much more relevant result for this query.
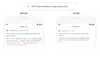
Let’s look at another query: “do estheticians stand a lot at work.” Previously, our systems were taking an approach of matching keywords, matching the term “stand-alone” in the result with the word “stand” in the query. But that isn’t the right use of the word “stand” in context. Our BERT models, on the other hand, understand that “stand” is related to the concept of the physical demands of a job, and displays a more useful response.
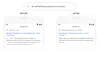
Here are some other examples where BERT has helped us grasp the subtle nuances of language that computers don’t quite understand the way humans do.
With the BERT model, we can better understand that “for someone” is an important part of this query, whereas previously we missed the meaning, with general results about filling prescriptions.
In the past, a query like this would confuse our systems--we placed too much importance on the word “curb” and ignored the word “no”, not understanding how critical that word was to appropriately responding to this query. So we’d return results for parking on a hill with a curb!
While the previous results page included a book in the “Young Adult” category, BERT can better understand that “adult” is being matched out of context, and pick out a more helpful result.
Improving Search in more languages
We’re also applying BERT to make Search better for people across the world. A powerful characteristic of these systems is that they can take learnings from one language and apply them to others. So we can take models that learn from improvements in English (a language where the vast majority of web content exists) and apply them to other languages. This helps us better return relevant results in the many languages that Search is offered in.
For featured snippets, we’re using a BERT model to improve featured snippets in the two dozen countries where this feature is available, and seeing significant improvements in languages like Korean, Hindi and Portuguese.
Search is not a solved problem
No matter what you’re looking for, or what language you speak, we hope you’re able to let go of some of your keyword-ese and search in a way that feels natural for you. But you’ll still stump Google from time to time. Even with BERT, we don’t always get it right. If you search for “what state is south of Nebraska,” BERT’s best guess is a community called “South Nebraska.” (If you've got a feeling it's not in Kansas, you're right.)
Language understanding remains an ongoing challenge, and it keeps us motivated to continue to improve Search. We’re always getting better and working to find the meaning in-- and most helpful information for-- every query you send our way.