Using symptoms search trends to inform COVID-19 research

Search is often where people come to get answers on health and wellbeing, whether it’s to find a doctor or treatment center, or understand a symptom better just before a doctor's visit. In the past, researchers have used Google Search data to gauge the health impact of heatwaves, improve prediction models for influenza-like illnesses, and monitor Lyme disease incidence. Today we’re making available a dataset of search trends for researchers to study the link between symptom-related searches and the spread of COVID-19. We hope this data could lead to a better understanding of the pandemic’s impact.
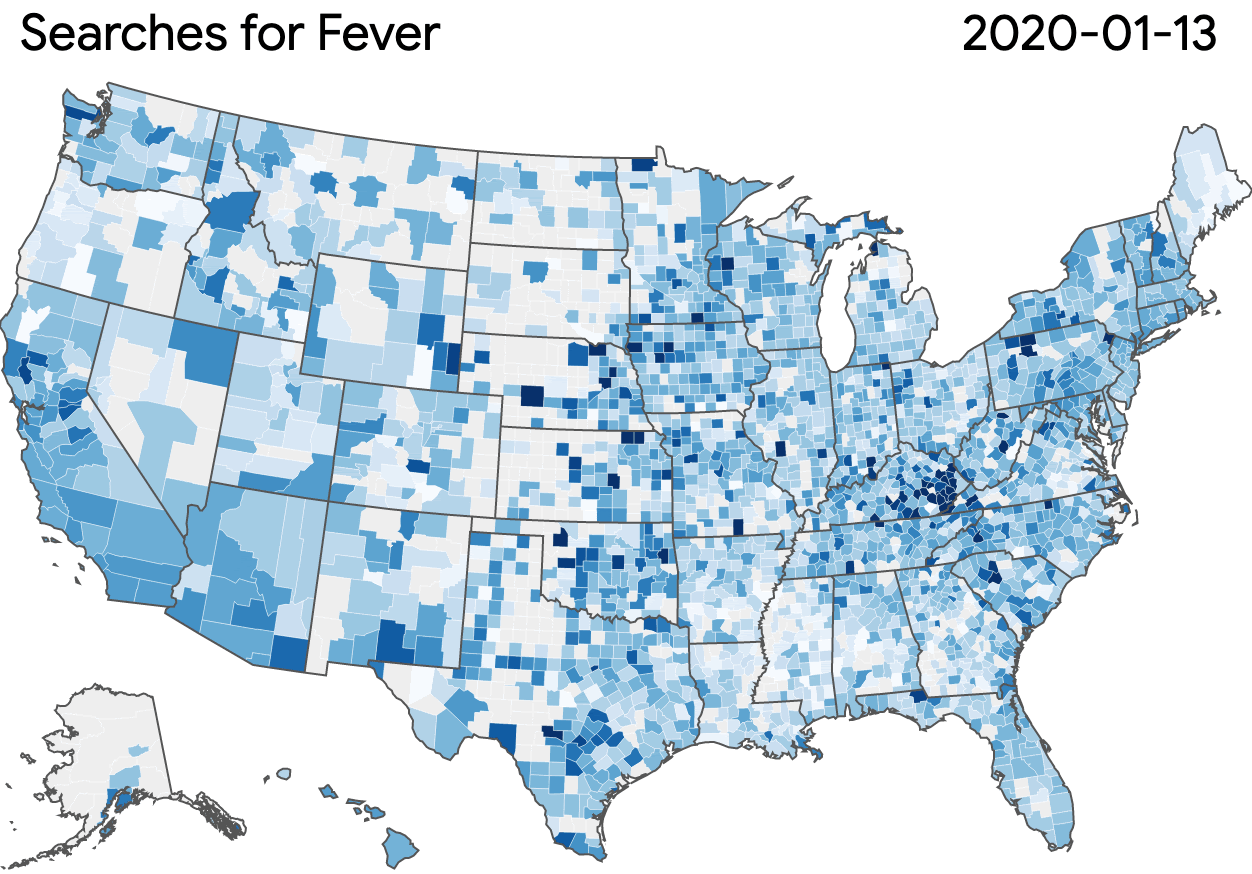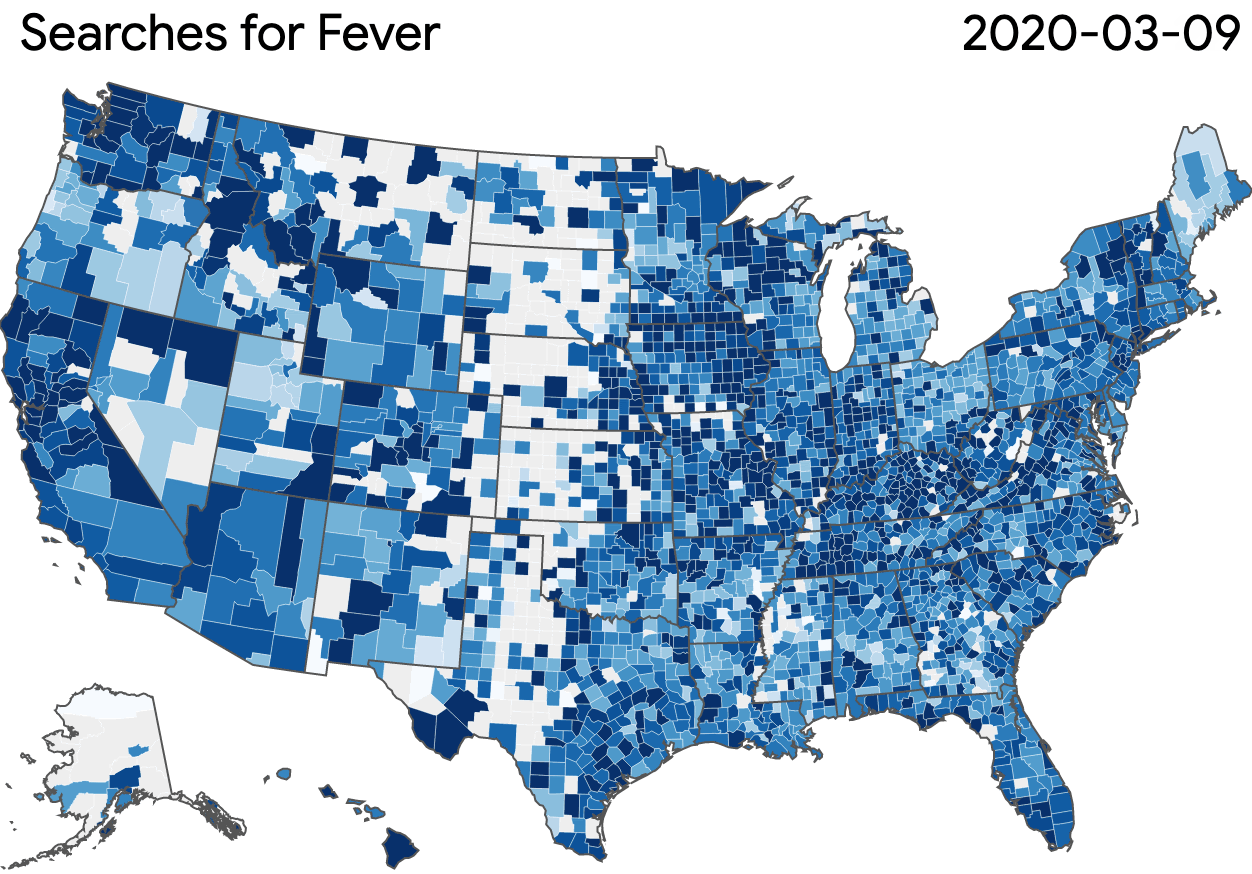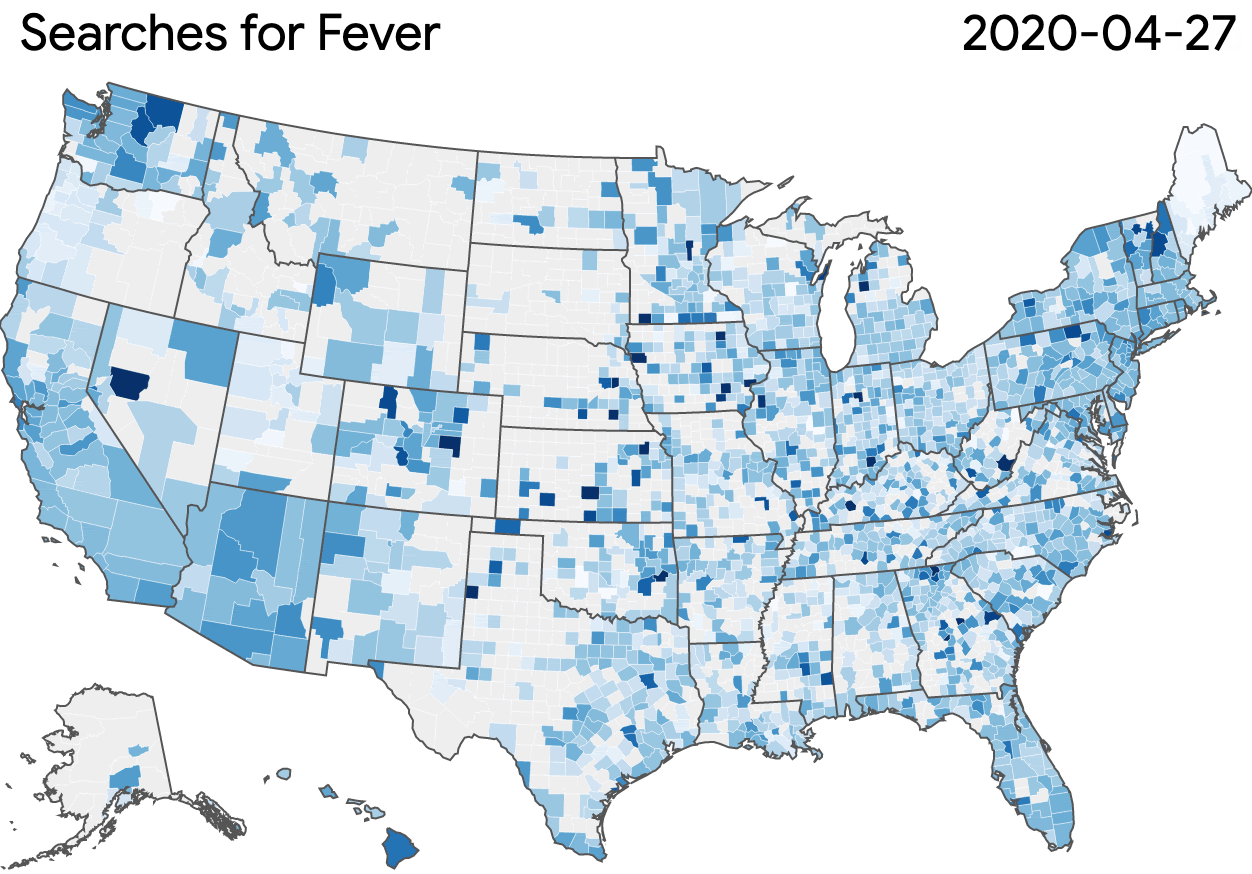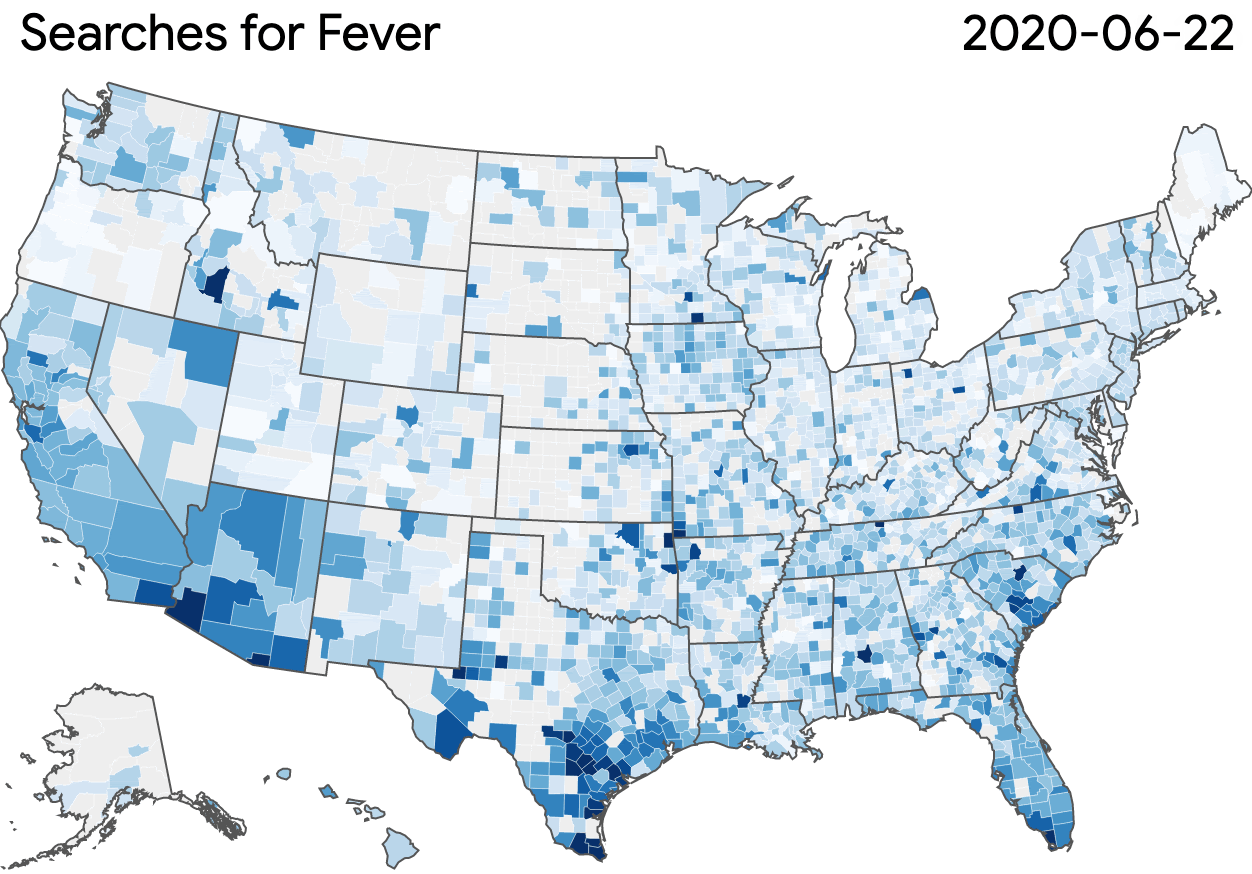
Using the dataset, researchers can develop models and create visualizations based on the popularity of symptom-related searches. This sample visualization is based on search volume for fever across the U.S. This visualization does not reflect the dataset’s user interface but shows what can be generated.
How search trends can support COVID-19 research
The COVID-19 Search Trends symptoms dataset includes aggregated, anonymized search trends for more than 400 symptoms, signs and health conditions, such as cough, fever and difficulty breathing. The dataset includes trends at the U.S. county-level from the past three years in order to make the insights more helpful to public health, and so researchers can account for changes in searches due to seasonality.
Public health currently uses a range of datasets to track and forecast the spread of COVID-19. Researchers could use this dataset to study if search trends can provide an earlier and more accurate indication of the reemergence of the virus in different parts of the country. And since measures such as shelter-in-place have reduced the accessibility of care and affected people’s wellbeing more generally, this dataset—which covers a broad range of symptoms and conditions, from diabetes to stress—could also be useful in studying the secondary health effects of the pandemic.
The dataset is available in Google Cloud's COVID-19 Free Public Dataset Program and is downloadable in CSV format from Google Research at Open COVID-19 Data GitHub repository.
Advancing health research with privacy protections
The COVID-19 Search Trends symptoms dataset is powered by the same anonymization technology that we use in the Community Mobility Reports and other Google products every day. No personal information or individual search queries are included. The dataset was produced using differential privacy, a state-of-the-art technique that adds random noise to the data to provide privacy guarantees while preserving the overall quality of the data.
Similar to Google Trends, the data is normalized based on a symptom’s relative popularity, allowing researchers to study spikes in search interest over different time periods, without exposing any individual query or even the number of queries in any given area.
More information about the privacy methods used to generate the dataset can be found in this report.
What’s next
This early release is limited to the United States and covers searches made in English and Spanish. It covers all states and many counties, where the available data meets quality and privacy thresholds. It was developed to specifically aid research on COVID-19, so we intend to make the dataset available for the duration of the pandemic.
As we receive feedback from public health researchers, civil society groups and the community at large, we’ll evaluate and expand this dataset by including additional countries and regions.
Researchers and public health experts are doing incredible work to respond to the pandemic. We hope this dataset will be useful in their work towards stopping the spread of COVID-19.