This content is generated by Google AI. Generative AI is experimental
[[duration]] minutes


Today, we are introducing Gemma 4 — our most intelligent open models to date. Purpose-built for advanced reasoning and agentic workflows, Gemma 4 delivers an unprecedented level of intelligence-per-parameter. This breakthrough builds on incredible community momentum: since the launch of our first generation, developers have downloaded Gemma over 400 million times, building a vibrant Gemmaverse of more than 100,000 variants. We listened closely to what innovators need next to push the boundaries of AI, and Gemma 4 is our answer: breakthrough capabilities made widely accessible under an Apache 2.0 license.
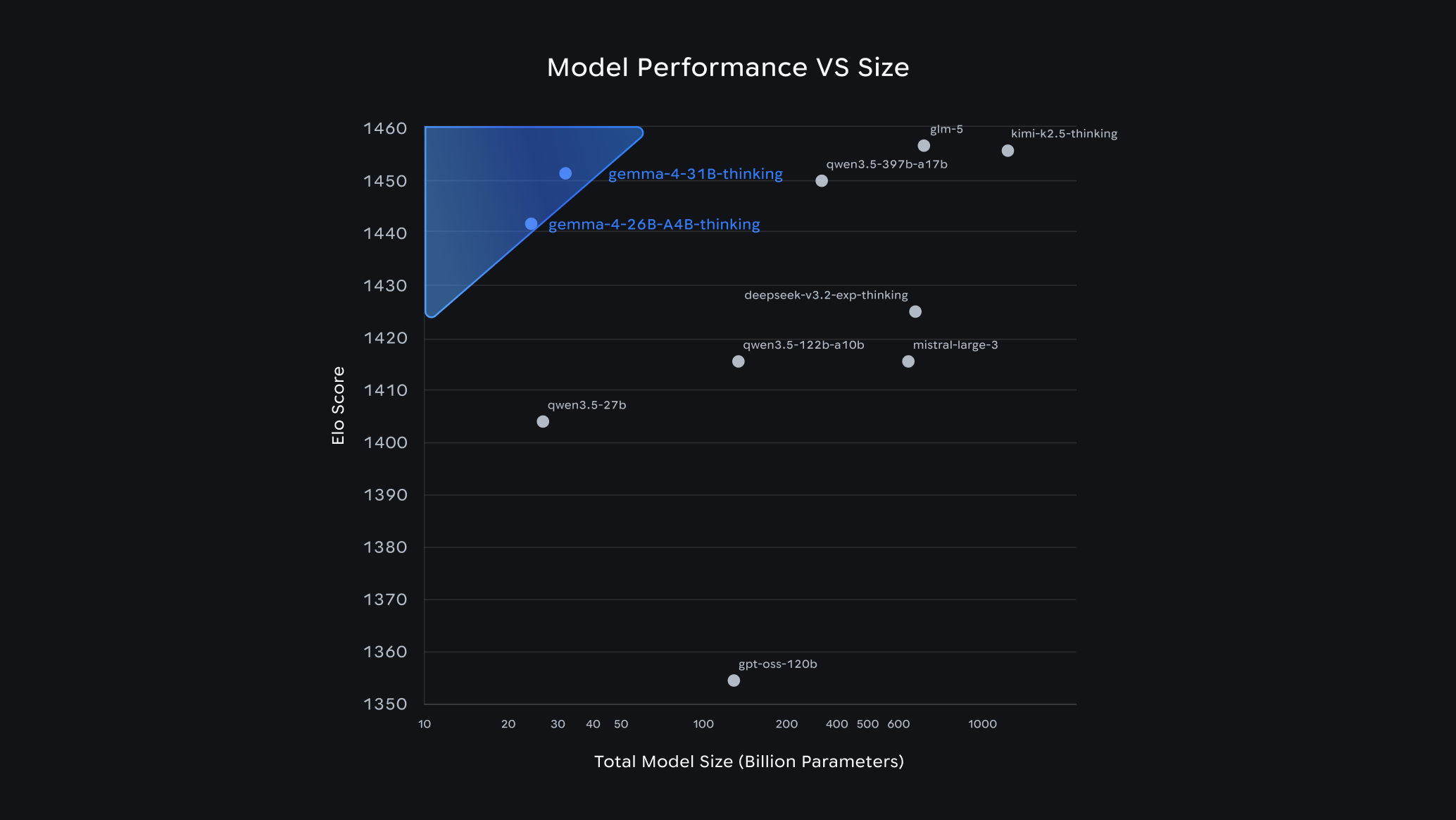
Open model performance vs size on Arena.ai’s chat arena as of 4/1.
Built from the same world-class research and technology as Gemini 3, Gemma 4 is the most capable model family you can run on your hardware. They complement our Gemini models, giving developers the industry's most powerful combination of both open and proprietary tools.
We are releasing Gemma 4 in four versatile sizes: Effective 2B (E2B), Effective 4B (E4B), 26B Mixture of Experts (MoE) and 31B Dense. The entire family moves beyond simple chat to handle complex logic and agentic workflows. Our larger models deliver state-of-the-art performance for their sizes, with the 31B model currently ranking as the #3 open model in the world on the industry-standard Arena AI text leaderboard, and the 26B model securing the #6 spot. There, Gemma 4 outcompetes models 20x its size. For developers, this new level of intelligence-per-parameter means achieving frontier-level capabilities with significantly less hardware overhead.
At the edge, our E2B and E4B models redefine on-device utility, prioritizing multimodal capabilities, low-latency processing and seamless ecosystem integration over raw parameter count.
To power the next generation of pioneering research and products, we've sized the Gemma 4 models specifically to run and fine-tune efficiently on hardware — from billions of Android devices worldwide, to laptop GPUs, all the way up to developer workstations and accelerators.
By using these highly optimized models, you can fine-tune Gemma 4 to achieve state-of-the-art performance on your specific tasks. We've already seen incredible success with this approach; for instance, INSAIT created a pioneering Bulgarian-first language model (BgGPT), and we worked with Yale University on Cell2Sentence-Scale to discover new pathways for cancer therapy, among many others.
Here is what makes Gemma 4 our most capable open model family yet:
We are releasing the Gemma 4 model weights in sizes tailored for specific hardware and use cases, ensuring you get frontier-class reasoning wherever you need it:
Optimized to provide researchers and developers with state-of-the-art reasoning on accessible hardware, our unquantized bfloat16 weights fit efficiently on a single 80GB NVIDIA H100 GPU. For local setups, quantized versions run natively on consumer GPUs to power your IDEs, coding assistants and agentic workflows. Our 26B Mixture of Experts (MoE) focus on latency, activating only 3.8 billion of its total parameters during inference to deliver exceptionally fast tokens-per-second, while our 31B Dense is maximizing raw quality and provides a powerful foundation for fine-tuning.
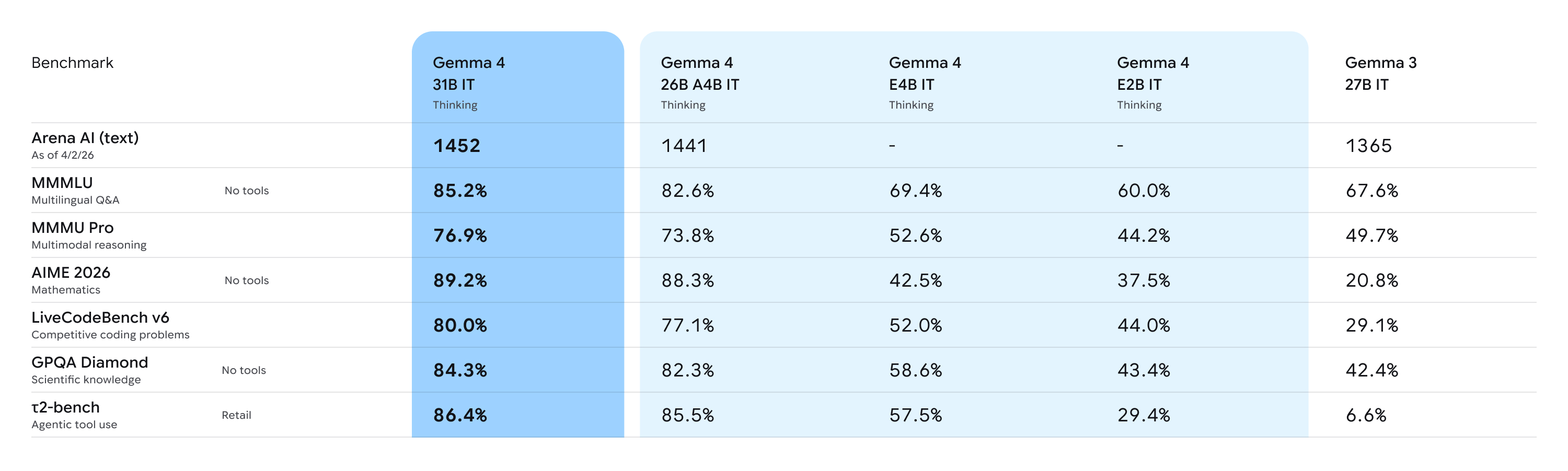
These models were evaluated against a large collection of different datasets and metrics to cover different aspects of text generation. See additional benchmarks in our model card.
Engineered from the ground up for maximum compute and memory efficiency, these models activate an effective 2 billion and 4 billion parameter footprint during inference to preserve RAM and battery life. In close collaboration with our Google Pixel team and mobile hardware leaders like Qualcomm Technologies and MediaTek, these multimodal models run completely offline with near-zero latency across edge devices like phones, Raspberry Pi, and NVIDIA Jetson Orin Nano. Android developers can now prototype agentic flows in the AICore Developer Preview today for forward-compatibility with Gemini Nano 4.
You gave us feedback, and we listened. Building the future of AI requires a collaborative approach, and we believe in empowering the developer ecosystem without restrictive barriers. That's why Gemma 4 is released under a commercially permissive Apache 2.0 license.
This open-source license provides a foundation for complete developer flexibility and digital sovereignty; granting you complete control over your data, infrastructure, and models. It allows you to build freely and deploy securely across any environment, whether on-premises or in the cloud.
These models undergo the same rigorous infrastructure security protocols as our proprietary models. By choosing Gemma 4, enterprises and sovereign organizations gain a trusted, transparent foundation that delivers state-of-the-art capabilities while meeting the highest standards for security and reliability.






