How AI makes virtual try-on more realistic


Today we announced virtual try-on for apparel, a new feature that shows you what clothes look like on real models with different body shapes and sizes. That includes those subtle but crucial details, like how something drapes, folds, clings, stretches and wrinkles. To do this, our shopping AI researchers developed a new generative AI model that produces life-like portrayals of clothing on people.
Let's take a closer look at this new AI model and how exactly it powers our virtual try-on (VTO) feature.
Generating try-on images with AI
Perhaps the most popular reference for VTO dates back to the movie “Clueless.” We’ve come a long way since Cher’s closet, though. Current techniques like geometric warping can cut-and-paste and then deform a clothing image to fit a silhouette. Even so, the final images never quite hit the mark: Clothes don’t realistically adapt to the body, and they have visual defects like misplaced folds that make garments look misshapen and unnatural.
So when we set out to build a new VTO feature, we were committed to generating every pixel of a garment from scratch to produce high-quality, realistic images. We found a way with our new diffusion-based AI model.
Our VTO technology produces high quality, realistic images.

To understand how this model works, let’s first explain diffusion. Diffusion is the process of gradually adding extra pixels (or “noise”) to an image until it becomes unrecognizable — and then removing the noise completely until the original image is reconstructed in perfect quality. Text-to-image models like Imagen use diffusion plus text from a large language model (LLM), to generate a realistic image solely based on the text you enter.
Inspired by Imagen, we decided to tackle VTO using diffusion — but with a twist. Instead of using text as input during diffusion, we use a pair of images: one of a garment and another of a person. Each image is sent to its own neural network (a U-net) and shares information with each other in a process called “cross-attention” to generate the output: a photorealistic image of the person wearing the garment. This combination of image-based diffusion and cross-attention make up our new AI model.
Virtual try-on for apparel lets you render tops on real models who resonate with you.
Training with Google’s Shopping Graph
To make our VTO feature as helpful and realistic as possible, we put the new AI model through rigorous training. But rather than training it with an LLM (like Imagen does), we tapped into Google’s Shopping Graph, the world’s most comprehensive data set of the latest products, sellers, brands, reviews and inventory.
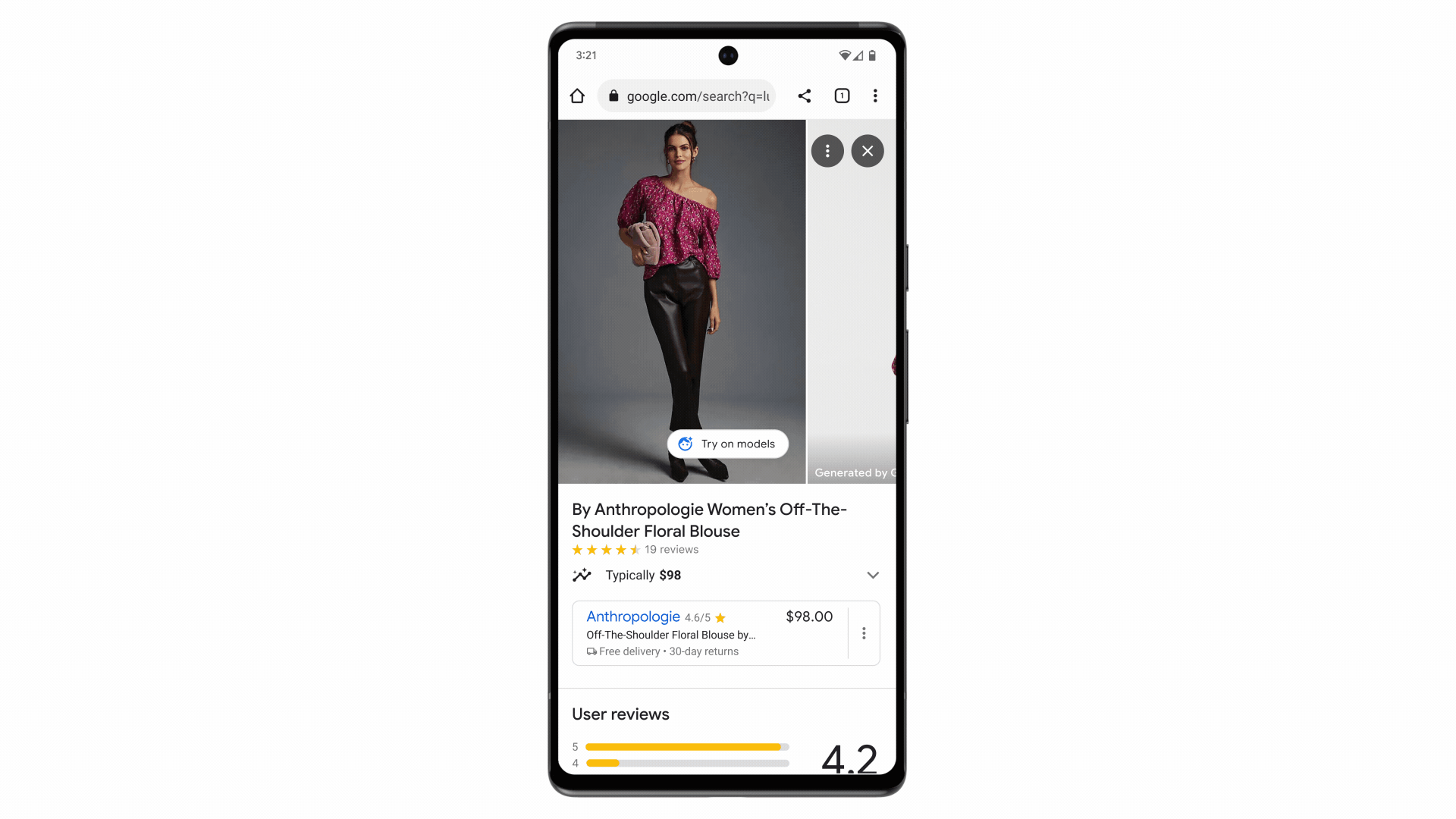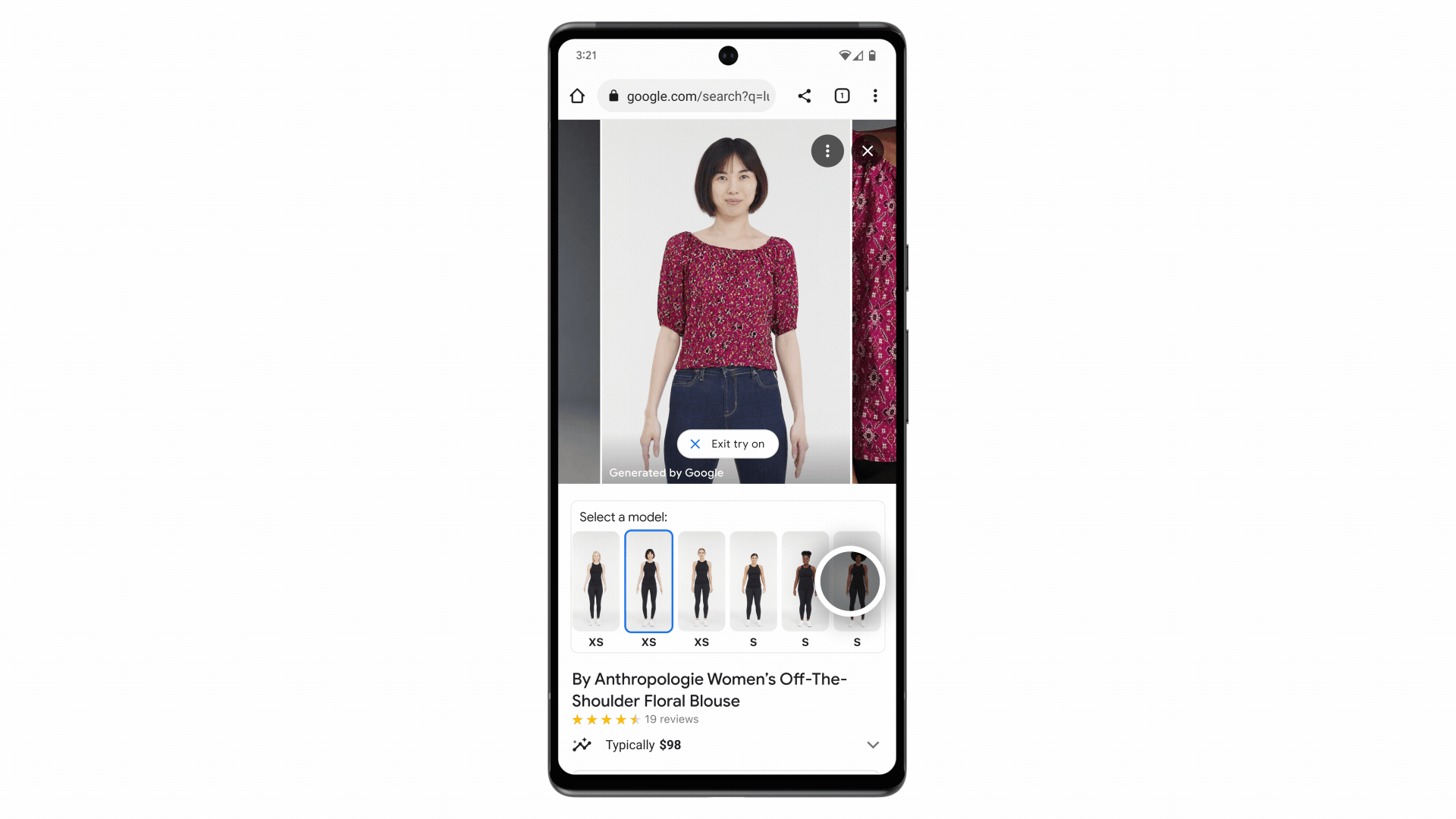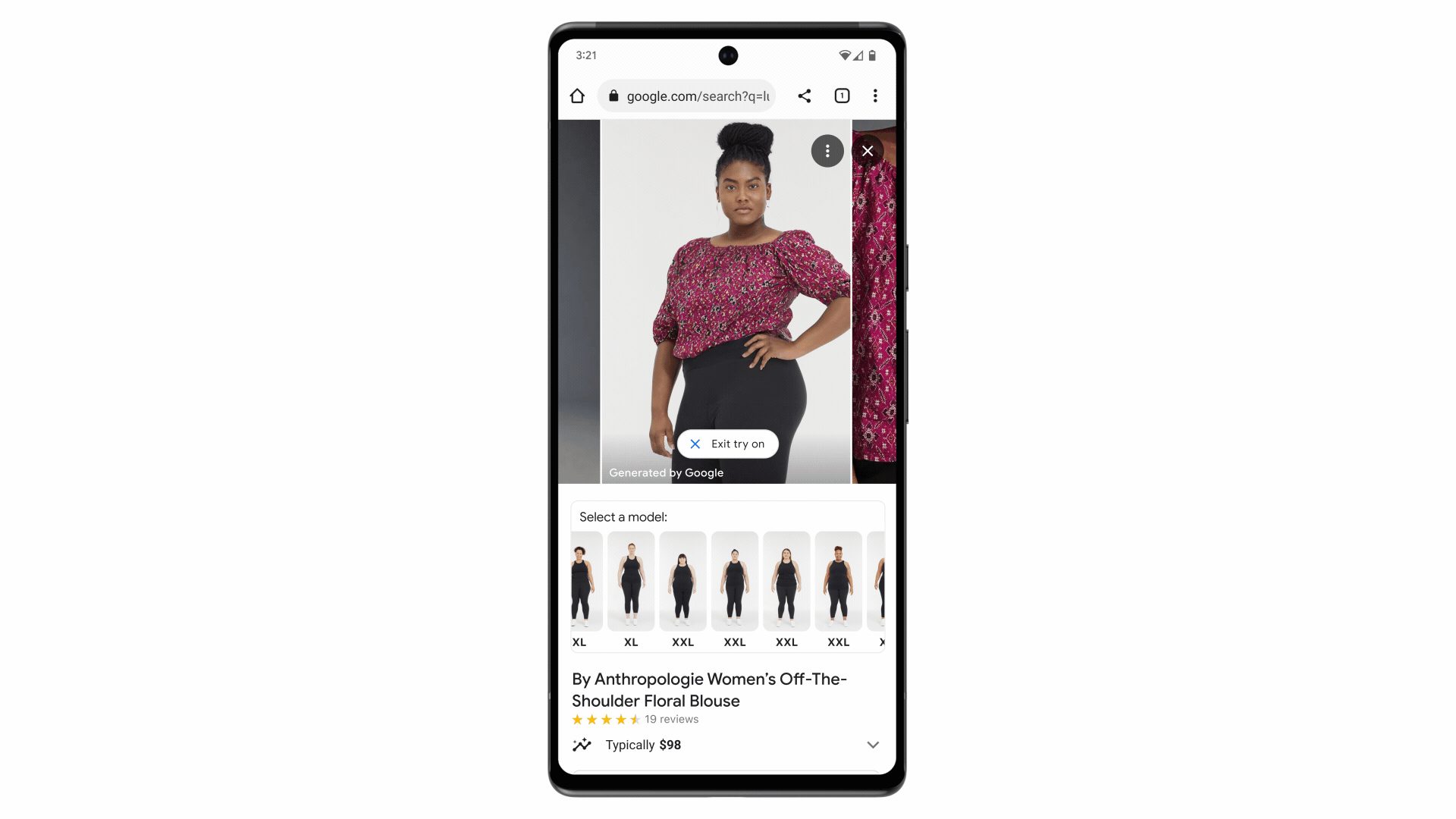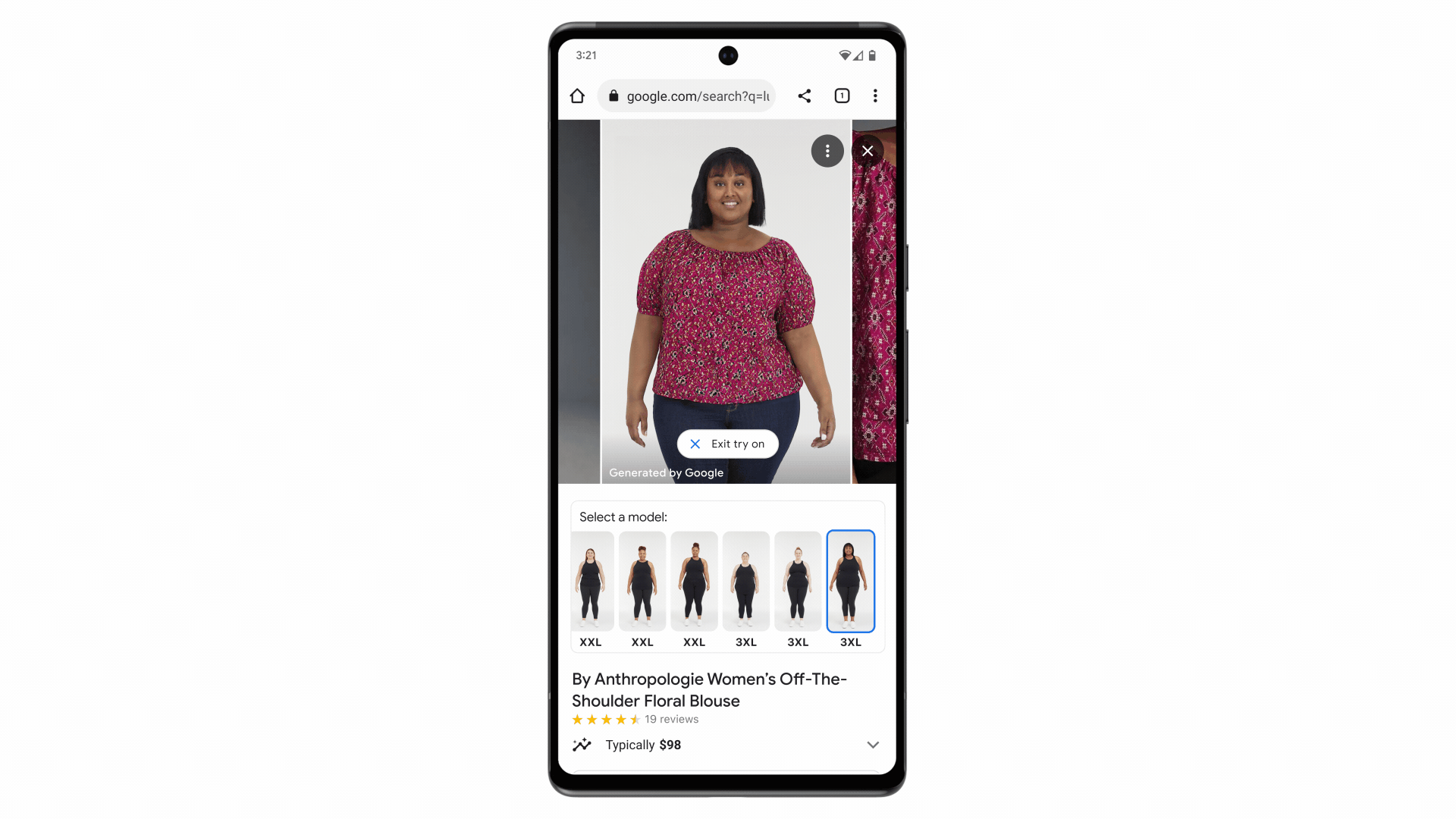
We trained the model using many pairs of images, each including a person wearing a garment in two different poses — let’s say, an image of someone wearing a shirt standing sideways and another of them standing forward. In this scenario, the AI model learns to match the shape of the shirt in the sideways pose with the person in the forward pose, and vice versa, until it can generate realistic images of the shirt on that person from all angles. To take it up a notch, we repeated this process using millions of random image pairs of different garments and people. The result allows you to see what a top looks like on the model of your choice.
Our diffusion model sends images to their own neural network (a U-net) to generate the output: a photorealistic image of the person wearing the garment.

Starting today, you can use virtual try-on for apparel on women’s tops from brands across Google’s Shopping Graph, including Anthropologie, LOFT, H&M and Everlane. Over time, the tool will get even more precise and expand to more of your favorite brands.
To learn more about the tech behind this feature, read our latest research paper.